Spark map算子学习使用详解
作者:高景洋 日期:2020-10-25 09:49:47 浏览次数:2206
map(func):
1、将func作用到数据集的每一个元素上,生成一个新的数据集并返回
2、map操作,相当于将RDD中每个Partition,中的每一个数据,都作用上一个相同的操作
如图:
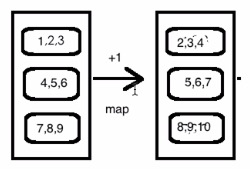
示例代码:
实现,将某个RDD中的数据+1。
def func_for_map(x):
return x+1
def my_map3(): conf = SparkConf().setMaster('local[5]').setAppName('sparkTest') sc = SparkContext(conf=conf) a = sc.parallelize([1,2,3,4,5,6,7]) b = a.map(lambda x:func_for_map(x))
print(b.collect())
sc.stop()
结果输出:[2, 3, 4, 5, 6, 7, 8]
本文永久性链接:
<a href="http://r4.com.cn/art148.aspx">Spark map算子学习使用详解</a>
<a href="http://r4.com.cn/art148.aspx">Spark map算子学习使用详解</a>
当前header:Host: r4.com.cn
X-Host1: r4.com.cn
X-Host2: r4.com.cn
X-Host3: 127.0.0.1:8080
X-Forwarded-For: 10.1.244.229, 216.73.217.64
X-Real-Ip: 216.73.217.64
X-Domain: r4.com.cn
X-Request: GET /art148.aspx HTTP/1.1
X-Request-Uri: /art148.aspx
Connection: close
Accept: */*
User-Agent: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Accept-Encoding: gzip, br, zstd, deflate
Via: 1.1 squid-proxy-5b96dc6d46-ts6z8 (squid/6.13)
Cache-Control: max-age=259200